直播回顾 | “数生智能 构建算存共同体”精彩观点
编者按:6月20日,主题为《数生智能,构建算存共同体》的专场直播在益企研究院视频号成功举办。益企研究院创始人张广彬(狒哥)主持了此次活动,与北京大学计算中心系统管理室主任樊春、希捷科技中国区市场营销负责人俞康、超聚变算力业务首席创新架构师梁永贵等行业专家进行了深入交流。
本文为此次直播的精彩观点整理,部分内容有删减。观看直播全文,请访问益企研究院视频号,观看直播回放。
人工智能快速发展的大背景下,如何看待算力与存力的关系?
狒哥:随着这几年 AI 和大模型的兴起,越来越多的场合用“算力中心”代替原有的“数据中心”。前一阵有朋友说,既然有算力中心,是否也应该有“存力中心”?我回答说,那“数据中心”是干什么的?虽然这么说玩笑成分居多,但也反映出AI 与算力和存力的一个关系。大家如何看待这些名词背后反映出的问题?

益企研究院创始人张广彬樊春:计算和存储就是相辅相成的,就像我们单位过去 60 多年一直叫北京大学计算中心。但是最近20多年大家听得更多的应该是数据中心,近些年开始有叫算力中心的。从国家管理的角度来说,在国家层面还是叫数据局、大数据局,叫计算的比较少。总体来说,还是强调以数据为核心,围绕数据的加工转换进行。

北京大学计算中心系统管理室主任樊春狒哥:的确如此,数据中心行业的历史并没有我们想象的那么长,历史上也有被称作计算中心、网络中心等等。不纠结名字的话,我们现在更关注的是AI和算力、存力之间的内容。
梁永贵:算力和存力其实都是在围绕数据服务。随着大模型的发展,模型参数的指数级增长,大家能够感受到对算力的急剧的需求,这导致了算力设施的价格飙升。但是随着大模型技术研究的深入,大家越来越发现要充分发挥AI的性能,仅仅提升算力并不足够,还需要在存力上进行协同。因此,存力也变得非常关键,算力与存力的协同发展,这几年备受重视。

超聚变算力业务首席创新架构师梁永贵首先,此前在大模型训练时,大家更关注算力成本,但是在今年稀疏性技术降低了对算力的需求,存储的成本开始凸显。很多开源的技术方案也在逐渐证实可以通过优化数据存储的路径,优化缓存策略,优化存储效率,从而整体显著提升大模型训练的性价比。随着AI技术的进一步深入发展,算力在不断的提升,对存力也提出了一些新的要求,包括要求存力能够提供更庞大的数据处理能力,或者更强的数据扩展能力。此外,在算力强大了之后,对数据的读写速度、读写带宽、读写延时,都提出了更高的要求。因此,在未来的AI发展过程中,会更加注重算力与存力的协同优化,包括通过软件和硬件的深度融合,然后实现计算资源和存储资源的动态调配以及高效利用。同时,AI技术的发展本身也会服务于存储系统,让存储系统变得更加智能,包括智能识别数据的访问模式、数据的重要性、数据的冷热程度等,以提升存储的能力,更好地为AI的算力发展提供服务。
狒哥:对,算力、算法、数据这三驾马车不可偏废。
俞康:在AI的发展过程中,存储越来越受到关注。根据IDC的数据,到2028年,数据总量将会增长到394 ZB,其中AI会生成100 ZB,占数据总量的25%,这就意味着AI对于存储的挑战非常大,不仅是容量,还有能耗、性能、稳定性等等。

希捷科技中国区市场营销负责人俞康更重要的是,随着AI的发展和数据重要性的凸显,很多国家在强调数据主权,已经有150左右的国家在指定相关的法律法规来管理数据主权,他们希望自己国家生产出来的数据留在所在国的管理权限之下。全世界有10000个左右的数据中心,80%的数据中心座落在10个国家内,按照数据主权的要求,其他的国家会出现大规模的数据中心建设浪潮。中国很多互联网企业都在筹划出海,其中有一个需求就是需要在运行的国家建设数据中心,以存储相关的运行数据。希捷的目标就是致力于做AI的数据基础设施,所谓“无存储不AI”。希捷希望能够跟北京大学、超聚变等更多的合作伙伴一起来建设更好的生态,帮助企业建立一个更好的数据基础设施底座,推动AI更稳定、更高效。
大模型发展的不同场景,对算力与存力有什么不一样的需求?
狒哥:大模型出来之前,大家觉得数据越来越多,都无法处理了;但是在大模型出来之后,好像全世界的数据都不够用了。大模型带来了对算力和存力的高度需求,那么在大模型的发展下,不同的场景,对算力和存力有什么不一样的需求?
樊春:大模型发展的场景,整体来说,大的部分就分为两个,训练阶段和推理阶段。在训练阶段,又可以分为前期数据收集和整理和针对海量数据进行挖掘、压缩,形成模型参数这两个场景。在收集阶段,数据需求量非常大,但是对算力需求就不够密集。到了训练阶段的第二步骤,就是迭代、优化参数时,让参数更能反映客观世界的知识,将海量数据压缩到参数里面存储,这个过程应该是计算更加密集型,对计算的需求量更大。之后是推理阶段,根据模型的不同大小,对算力的需求和存储需求也是不一样的。
狒哥:樊老师提到的很重要的一点,就是在数据的预处理或者说前处理的阶段。我们益企研究院在年初联合希捷撰写了一本白皮书,叫做《AI时代的存储基石》,在写作的过程中,我们发现,整体而言,在大模型的训练过程中,大家在预处理方面提及不够多,显得对这个阶段的重视程度不太够,不知道这是不是一个普遍现象?
梁永贵:我觉得在训练阶段,算力和存力这两方面都会面临很高的压力。在训练阶段,首先对算力的需求很大,之前有数据表明,训练一个千亿的模型,需要数千台的AI服务器,持续运行20天以上,对算力的压力非常大;同时,在存力方面,由于训练的时候需要大量数据,以及训练过程中的checkpoint(检查点)的数据,以及相关的各种结构化、非结构化的数据量都非常巨大,可能都在PB级甚至EB级的这种数据,这些数据对存储也会造成巨大的压力。要求存储具备高带宽、低时延的能力。同时,在推理阶段,对算力的需求相对而言小一些,但是这个阶段会更关注算力和存力之间的均衡。在算力需求方面,如果是万亿参数规模的大模型,他们除了依赖高算力之外,还要通过稀疏算法、压缩技术等来降低对算力的要求。其实现在随着大模型的发展,已经有一些达到了万亿参数的规模,使用单芯片的算力已经到极限,单靠算力的堆叠也很难继续,因此大家已经会考虑转向存力方面去发挥,也就是以存代算概念出现的背景。这样的话,企业就能够减少对算力的需求,当然同时也会把压力转移到了存储上面,但是二者之间如果要一个更好的性价比,就需要做好算力和存力之间的平衡。因此,在存储方面,企业需要依赖更高的IOPS、更低的时延;对于大规模的应用,需要考虑更长期的历史对话,以分级的冷热数据将其存下来,包括存储到HDD上面来降低整体成本。
狒哥:以存代算是一个很好的思路。那么,存储企业该如何做好应对呢?
俞康:从希捷的角度来说,一直都做好了相关的准备。在大模型的基础设施架构上,就是两大块,一个是计算集群,包括一些高性能的处理器,CPU、GPU、HBA、HBM、DRAM、SSD等;另外一个就是存储集群,应用最后产生的数据,都会到存储集群中,它就是网络的HDD或者SSD。计算集群对时延要求高,在纳秒级;而存储集群的时延在毫秒级就可以。最终数据都是会流向大容量硬盘,作为长期的保存。
樊春:我们学校也建立了很多计算集群和存储集群,为学校进行科研和教学的服务。存储集群是始终受到特别关注的,因为计算集群坏了一两个节点,并不影响整体任务的运行,而存储集群一旦损坏,基本上计算集群就不能工作了。因此,我们会尤其关注存储集群的稳定性、可靠性和性能,当然还有关注存储集群的节能水平。
在AI的生命周期中,哪个环节的数据存储需要受到加倍的重视?
狒哥:从樊老师的现身说法来看,数据的确非常重要。但是从另外的角度来说,也不一定所有的数据都那么重要?比如说有一些数据某一个瞬间很重要,但不一定有长期保存的必要?在AI的生命周期中,哪些环节的数据存储需要加倍的重视?
俞康:聊到生命周期,并不只是说有一个既定的出生时间和死亡时间,我们认为它有一个循环,就是类似于莫比乌斯的那个环,它是一个整体循环,是一个不断螺旋的增长过程。从一开始,AI需要很多的数据,即数据源,它可能是需要PB级甚至EB级的高质量、大批量的数据,这就有对存储的巨大空间需求;然后再训练、推理环节,有checkpoint环节,以及历史数据的回溯、模型的优化等需求,都需要很多的存储空间。等模型完成,在生成数据环节,数据生产出来之后也需要存储,可能需要很多长期存储,对存储集群的需求也许会更大,很多数据最终都会流向大容量硬盘。当然,这些数据将来又会反哺到模型的训练中。这就是一个整体的循环过程,是一个整体的生命周期。历经循环之后,模型训练就会越来越智能,越来越聪明。
狒哥:对,这种无限循环,并螺旋向上的过程,希捷有一张很好的图片,我一直很喜欢,就是下面这张。我们在《AI存储白皮书》中也用到了。
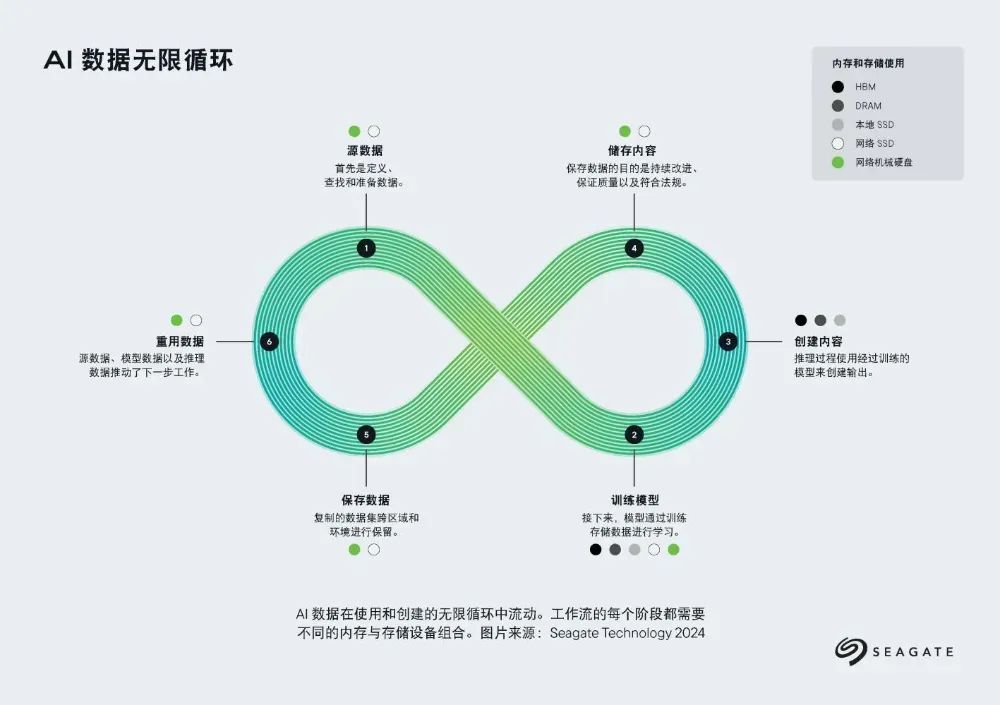
樊春:在大模型训练整个过程中,数据不仅像生命生长的过程,更像是一个轮回,一遍又一遍的周而复始,并且在这个过程中提升。这几年有一个很著名的科研成果叫做AlphaFold,这是一个关于蛋白质结构的问题。它的模型的基础,一方面是分子动力学等理论作为基础,另外一方面在于很多的数据,来自冷冻电镜测量的结构数据。包括施一公、颜宁等科学家都是通过冷冻电镜的数据分析出关键的生物结构,在这个过程中,AlphaFold就是利用这些科学家分析出来的结构训练而成。每一个结构是原始采集而来的照片而成,在形成AlphaFold的时候,已经有数以万计甚至十万计的三维分子结构,而每一个三维结构又可能是几万、上百万甚至上千万的图片进行合成计算的成果,这就会涉及到几十万倍的数据。因此,尽管AlphaFold是一个不太大的模型,但是它的数据源从底座开始到得到分析结果,需要的是一个海量的存储空间。
狒哥:从数据生命的轮回到蛋白质的结构所需要的存储,樊老师的例子深入浅出,很好的讲述了存储的价值。
梁永贵:数据的确重要,在AI中,如何设计数据的存储方案?我们认为,应该要从四个方面入手,数据的采集和预处理、训练、推理、模型的迭代。数据的采集和预处理这部分业界强调的不多,但是原始数据的确是需要清洗、标注和格式化等才能够正常使用。因此,对于存储来说,它就要求必须具备高吞吐和低延时的能力,并且容量要大,还需要支持弹性的扩容。其次,在模型的训练阶段,重点是高频的文件读写和并发,这是为了避免GPU等待数据,以避免算力的空转。第三个,在推理阶段,现在很多的技术重点在于KV Cache(键值缓存)的管理,以便提升KV Cache的调度速度和存储速度,以便提升推理的响应效率和时间。在这种情况下,就特别要关注键值存储的性能。最后,在模型的迭代阶段,企业希望将自己的数据应用到AI中,比如说利用RAG技术,它也是一个迭代过程,它可能会用到一些冷数据,那就需要企业的存储具备冷热数据的分级能力,甚至对于冷数据有压缩的能力,以降低存储的成本。在这种场景下,HDD就会有很大的作用。
面对AI带来的算力和存力挑战,该如何创新以应对?
狒哥:无论是AI还是大模型其他领域的创新,每几个月就会出现一些新的变化,给计算和存储带来一些新的挑战。那么超聚变和希捷有哪些创新来应对,从用户的角度又该如何辨析和解决?
俞康:希捷一直在布局,如何为AI时代爆炸性增长的数据奠定更好地数据基础底座。不像之前大家所熟悉的硬盘迭代,只是1TB、2TB的容量增长,甚至到了一定的阶段之后,容量要增长,只能往里面放置更多的碟片。而希捷不一样,希捷在做持续的创新,在这个领域可以算是世界领先。在去年,希捷发布了一个新的平台魔彩盒3+(Mozaic 3+)。它基于新的技术HAMR(热辅助磁记录),能够大幅度地提升单碟片面密度。
梁永贵:对于超聚变而言,一直致力于做全球领先的算力服务和算力基础设施提供商。超聚变一直在多个维度推出相关技术和新产品,在算力基础设施领域,我们最近推出了FusionPoD for AI整机柜液冷服务器,它通过液冷技术降低能耗,提升算力效能,适配大模型训练所需要的高密度算力。在标准液冷服务器市场,超聚变已经连续两年中国市场份额第一,也牵头成立了液冷AI开放联盟,参与了液冷整机柜服务器行业标准等,推进液冷产业高质量发展。此外,除了服务器之外,超聚变也在内存池化等方面进行了深入的研究,在行业内率先推出了内存池化的解决方案,它能够提供超大容量的内存,将内存与算力解耦,供多个节点进行弹性分配,且内存中的数据多个节点可以直接共享的方式来访问数据,这可以极大地缩短数据在各个节点之间的网络传输时间。
狒哥:我们在《AI时代的存储基石》中也引用了希捷的另外一张图片,其中提到相关的数据从处理器到HBM、DRAM、本地SSD、网络SSD和网络HDD等。其中DRAM、CXL等都能池化,这个图还有迭代更新的空间。
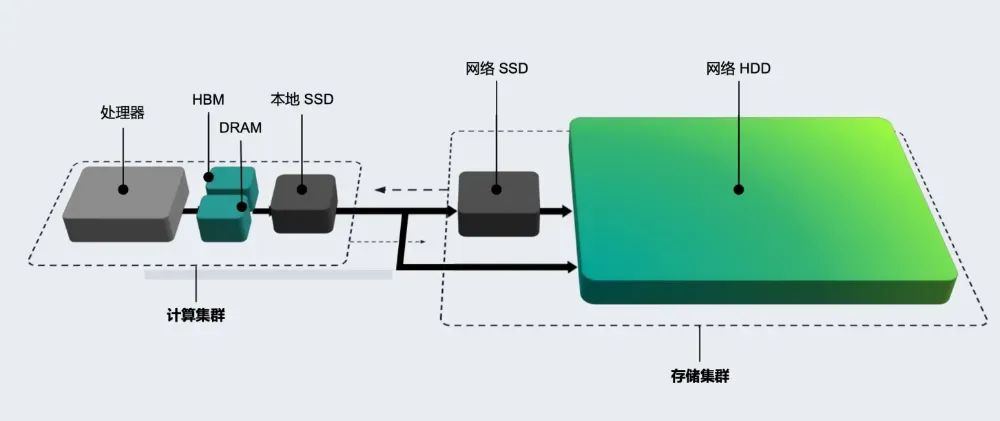
梁永贵:对,内存的独立和池化趋势,现在已经是业界的共识。只是该技术的大规模应用还需要更多厂家的参与,推动整个生态的建设。针对存算协同的需求,以及针对大模型带来的存储挑战,超聚变也推出了FusionServer 5298 V7,它是新一代4U2路机架服务器,能够支持最多60块硬盘,也将会支持希捷的最新魔彩盒3+,届时它的存储容量将达到新高。这样就能够更好地满足分布式存储、大数据、归档等业务的需求。AI也会用到一些历史数据,那么归档存储就能够更好的满足海量数据的需求。通过FusionServer 5298 V7提供的存储容量,能够降低每单位存储成本,对于客户来说是很好的降低成本、提升竞争力的方案。
狒哥:其实CXL、HAMR这些技术并不是最近才开始研究的,但是到真正成熟到能够被应用,需要相当长的一段时间。比如说,HAMR技术,什么时候才能够真正商用、大规模量产?以及面对的是什么样的市场?
俞康:其实希捷应用了HAMR(热辅助磁记录)技术的魔彩盒已经在去年上市,并且从发货量上来看,已经是发货了100万片给超大规模云计算厂商。我们跟超聚变也已经展开了合作。
梁永贵:希捷的魔彩盒3+(Mozaic 3+),在超聚变已经通过了产品的引入测试,很快就能够投入到生产中,为将来的AI发展提供有力的支持。在跟希捷的合作过程中,我们共同发现高可靠、低功耗、大容量的硬盘,是新一代智能架构的刚需。从超聚变的测试情况来看,希捷的魔彩盒3+(Mozaic 3+),不仅能够实现更优的单位空间存储能力,还能够实现每PB存储成本的大幅度降低和TCO的降低。以及,在数据中心整体功耗控制、运维效率等方面都会有显著的价值体现。
狒哥:作为厂商,把存算协同的事情做好了,对于樊老师这样的用户而言,那就是躺赢了。
樊春:对,从我们的角度来说就是享受到了成果。现在北大计算中心的最新的算力集群,就是由超聚变提供的,用的是超聚变的液冷服务器,存储也是希捷的产品。对于希捷的新一代存储产品,能够提供更好性价比、更加绿色节能的能力,那对于我们用户来说,就直接能够得到节省成本、提升效率的好处。期待着能够尽快使用新一代的产品。
梁永贵:我们不仅推出前面所说的基础设施产品,超聚变也有AI解决方案来应对AI的快速发展,包括我们发布的FusionPoD for AI这种大模型解决方案,它能够覆盖我们前面提及的数据预处理、模型训练、推理的整个生命周期。并且,这个解决方案里面,超聚变兼容了多元算力,也继承了AI加速的软件栈,以及相关的资源编排能力调度的系统,能够支持多种算力的统一化管理和优化,来提升整体的算力利用率和执行效率。此外,超聚变还将一些软件的组件和服务都封装了进去,使得企业能够在多样算力调度和模型加速方面,能够有效的缩短算力到应用的距离。因此,这个FusionPoD for AI就能够加速实现从纸面算力到好用算力落地的过程。
狒哥:樊老师作为用户,一定会基于产品的创新基础上,迭代出自己的创新,来应对未来的挑战。
樊春:是的,我们和超聚变在一体机上面,也有深入的合作,关于训推一体等多个方面。此外,我们也做了一些相应的训练和推理的软件栈,和超聚变的产品配合,也进入了超聚变官方的下载列表,可以对外进行销售。所以,我们很荣幸地进入超聚变的销售体系,我们不仅是超聚变的客户,也是超聚变的合作伙伴。
AI和智能体的发展,算力和存力的变革和创新,会在哪些行业产生影响?
樊春:我觉得首先会在教育科研领域产生非常大的变革,国家非常重实将AI相关技术引入到教育和科研、服务当中。最典型的是,我们学校就产生了大量的服务老师和学生的各种智能体,可以帮助同学们尽快地学习和掌握知识。另外,AI和AI技术的发展,也会帮助我们科研的很多领域进行发展,比如说关于气候的碳排放模拟,碳排放对温室效应的影响等等。气候的模拟需要大量的数据,从中找到规律进行预测,这是很重要的领域。另外在生命科学领域,又分为两个具体的领域,一个是基因工程,另外一个是关于成像工程。这个成像工程分为多模态跨尺度的。从非常低尺度的分子结构,到细胞结构到全人体等,有非常多的尺度都有着大量的成像数据。
还有就是关于拓展人类的认知的问题,比如说现在的引力波相关、给黑洞拍照片等,都是大家非常关心的话题,这些都离不开海量的数据处理和海量的存储。整个AI以及存储技术的发展,能够极大地促进科学领域的发展,以及教育领域的发展。
梁永贵:对于未来AI的发展来说,行业的发展一定是一个百花齐放的状态,不一定会是哪个行业领先,只是有一些领域的应用可能会早一些,有一些领域会晚一点。因此,未来肯定很多领域都会被AI渗透,只是渗透的程度会有所不同。在多行业的发展情况下,那些对非结构化数据处理以及复杂模型训练要求较高的领域,可能会发展的更好一些。比如说医疗领域,它会有很多的医学图片的数据、病例的数据,那就会促进多模态大模型的发展,以提高医生诊断的效率,甚至辅助医生做诊断。在科研与大模型训练的领域,比如说天文气候等领域,其数据量会更大,达到EB级别。超聚变跟某地的气象局,也进行了合作。通过超聚变的FusionOne的大规模的加速引擎,对其PB级别的数据进行了高效的处理,这个引擎就是集成了超聚变AI的开发平台,包括资源调度、加速等组件,再结合其内部的存储和算力融合在一起,就可以把分布式存储跟算力深度融合在了一起,这就能够解决气象预测过程中整个数据的吞吐量的瓶颈,以及大模型的训练时间的瓶颈。
其次,在智能制造领域,超聚变也有涉足,将FusionOne的HCI超融合方案,将虚拟化与存储进行了融合,降低了部署的门槛。在智能制造行业,利用内部的AI中台以及高速缓存,可以实时分析工业影像的相关信息,帮助企业实时检测到缺陷,快速识别,甚至可以做提前的预测。这就可以帮助到智能制造行业的企业,提升效率。
俞康:除了上面提到的这些领域,我们认为AI还可以在更多行业发挥作用,比如说金融,能源电网等等。有客户对希捷表示,因为AI导入到了它的智能监控系统,因此需要更多的存储空间。此外,提到智能制造,在很多年前,在AI还没有这么火热的时候,希捷就已经将智能制造能力运用到了自己的工厂里面,在工厂的生产流程和产品质量管控方面,都是有着很好的实践。在希捷内部,差不多有着上千个AI的应用,有一些甚至是行业中的典范,比如说在硬盘的碟片检测流程中,不可能依赖人工去检测,而是采用智能化的方式,用AI的能力来检测,有问题就进行标记,极大地提升了硬盘碟片的检测效率,这对于希捷的产品生产质量的管理有着极大的帮助。
狒哥:在我们的《AI时代的存储基石》中,我们认为不能写“AI存储”,因为我们要写的是“storage for AI”,当然反过来,就像康总前面提到的,AI也可以“for storage”,这又体现了一种循环。包括英伟达在内,大家都喜欢AI工厂,英伟达的黄仁勋就总是讲数据中心就像一个AI工厂,这个的确是一种方向,AI将会给包括智能制造在内的千行百业提供支持,在各个行业都大有可为。