CPU也能“推”动大模型了?
刚刚过去的2023年很短又很长,短如英特尔在年头和年尾连更了两代至强CPU,长如大语言模型基础设施的战场已从训练蔓延到推理。
英特尔CEO帕特·基辛格(Pat Gelsinger)的类比很有代表性:只有少数机构(如国家气象局)需要建立天气预测模型,但每个人都想看天气预报。依此推之,大模型的推理市场也应该比训练市场大得多。
在2023云栖大会上,狒哥偶遇一位与阿里云有合作的CPU行业人士,说CPU做大(语言)模型的推理,最大的难点不在计算能力,而在内存带宽。
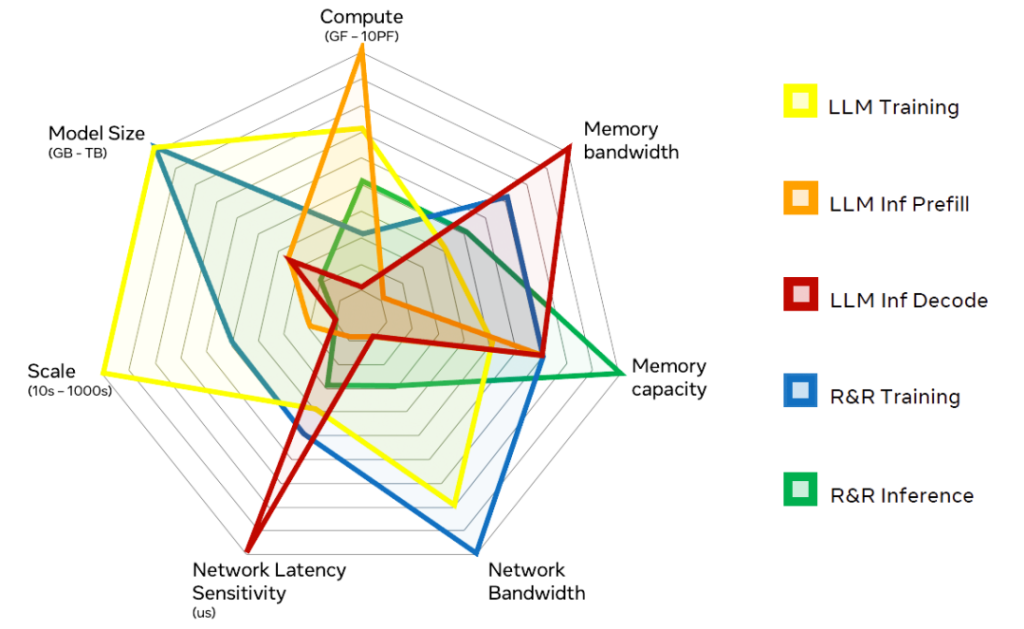
这让我想起两周前的2023 OCP(Open Compute Project,开放计算项目)全球峰会,Meta在主题演讲中,从算力(Compute)、内存和网络等维度,对比了大语言模型(Large Language Model,LLM)和排名/推荐(Ranking and Recommendation,R&R)系统在训练与推理环节的不同需求。
可以看出,同一类模型的推理(Inference)与训练(Training)场景在维度组合上不能说完全相反,也是各有侧重。那能不能说,在大模型(对应LLM,下同)的训练完成后,高性能GPU就不那么难以替代了呢?
用户使用推理服务,希望获得较低的时延(latency),和较高的吞吐率(throughput)。具体到大模型的推理任务,又可分为Prefill(预处理)和Decode(解码)两个阶段,在计算、存储(内存)和网络方面的要求,也是不同的。
中小参数模型,通用计算优选
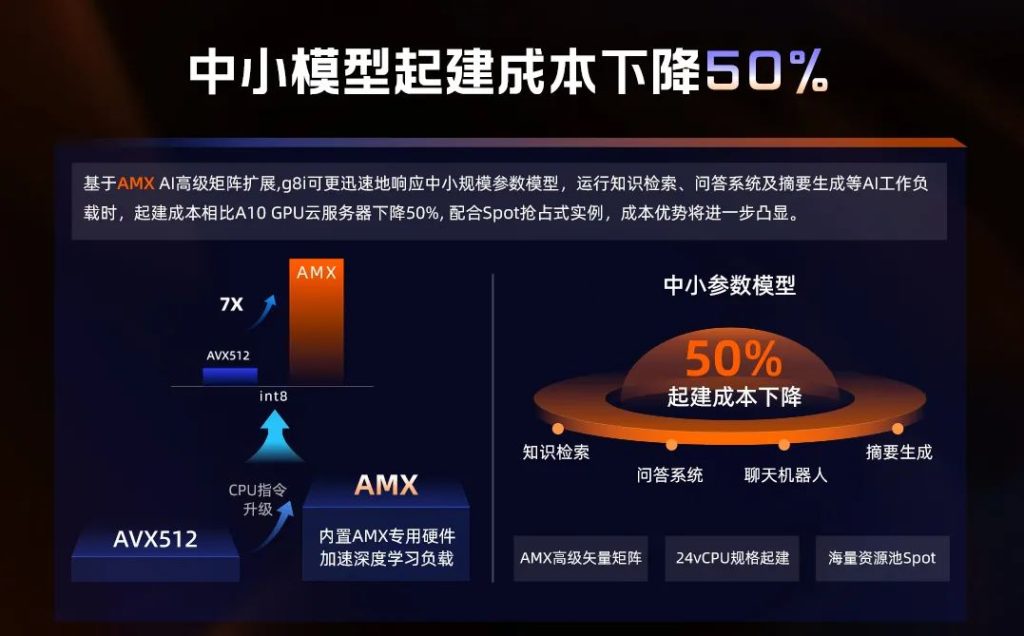
Prefill阶段通过理解输入文字生成第一个token,首包时延主要受限于并行处理能力和浮点运算能力(计算)。而在很多人印象中并不以算力见长的CPU,这方面的“理解”能力其实已经不弱。以阿里云第八代企业级通用计算实例ECS g8i为例,其最新升级的第五代英特尔至强可扩展处理器(代号Emerald Rapids,简称EMR),每个CPU核心除了传统的向量计算指令集AVX-512,还新增了矩阵计算指令集AMX(Advanced Matrix Extensions,高级矩阵扩展)。与上一代实例相比,当采用INT 8矩阵计算时,阿里云ECS g8i的性能提升达到7倍。
加上阿里云ECS g8i所基于的CPU核心数比上一代提高50%,来到48核心96线程,并行处理能力也得到增强。据阿里云弹性计算高级产品专家姬少晨介绍,使用24 vCPU规格的ECS g8i实例,运行70亿参数的通义千问模型,推理速度达到首包时延小于1秒、每秒生成12个token。根据通义千问平台广泛实践得出的经验值,在模型对话中,首包时延控制在3秒内,生成速度大于每秒5个Token,就基本具备可商用的状态。以中文推理模型来说,1个Token就是一个词,两三个字;5个Token就是5个词,每秒15个字,可以满足实时的阅读速度。

阿里云弹性计算高级产品专家 姬少晨
姬少晨认为,ECS g8i实例在60亿到130亿中小参数模型上的优势较为明显。60、70亿参数的情况下,使用24 vCPU的起建成本只有传统GPU方案的一半;规模扩大到130亿参数,由于CPU实例的内存容量更大,起建成本可以降低至四分之一。当前的GPU获取难度会持续一段时间,在可预期的未来,GPU的价格不会大幅下降。通用计算则不然,尤其阿里云有海量的资源,CPU的可获得性会好很多。而且阿里云有灵活的售卖模式,譬如通过Spot抢占式实例,客户可以拿到相对目标价极低的价格,结合实际的业务模型和业务落地过程,起建成本还能进一步下降。从这个维度来看,跑中小模型用通用计算是一个很好的选择。
超大参数模型,极致横向扩展
规模进一步扩大,问题有点复杂化。I/O取代算力,成为主要矛盾。
Decode阶段顺序输出后续的token,吞吐性能受限于内存带宽和网络时延。采用HBM(High Bandwidth Memory,高带宽内存)的GPU和CPU(如英特尔Xeon Max),在内存带宽上具有较为明显的优势。

英特尔数据中心和人工智能集团至强客户解决方案事业部总经理 李亚东
第四代英特尔至强可扩展处理器(代号Sapphire Rapids,简称SPR)支持DDR4-4800,内存带宽比g7依托的第三代英特尔至强可扩展处理器(代号Ice Lake)高50%,考虑到核心数的增长,平均到每个CPU核心的内存带宽不变。第五代英特尔至强可扩展处理器支持DDR5-5600,且与第四代英特尔至强可扩展处理器共平台,这意味着后续的ECS g8i实例可获得六分之一的内存带宽增益。最大的单点提升来自L3 Cache或曰末级缓存(LLC)容量,阿里云定制的最新款铂金(Platinum)处理器配满了320MB,比第七代实例的六倍还多。
在单个实例内存带宽不足的情况下,通过多个实例组成集群的横向扩展,来满足超大规模参数模型的推理需求,这就对网络时延提出了较高的要求。传统的VPC集群受限于接近20微秒(μs)的网络时延,4个实例的集群只能获得2倍多的性能;ECS g8i实例基于阿里云新一代CIPU架构,采用自研的弹性RDMA(eRDMA),把网络时延压低至8微秒,相应的集群效率提升到接近90%,即单实例性能的3.36倍。

在eRDMA集群的加持下,4个96 vCPU的g8i实例联手,运行通义千问刚刚开源的720亿参数超大模型,在输入小于500字时,首包时延在1秒多,最差的时候不高于3秒,每秒生成7个Token。720亿模型回答的问题质量比70亿和130亿高很多,所以大模型场景中也能有CPU的用武之地。

阿里云弹性计算产品线副总经理 王志坤
阿里云继续挖掘CPU大内存容量的潜力,将24 vCPU的内存配比调整为1:8,就可以容纳FP16精度的720亿参数模型。缺点是响应速度下降了一个数量级,较为适合对实时性要求不高的实验场景或离线场景,通过设置超大的batchsize(>32),让CPU的算力持续高并发运行,AMX性能的提升会进一步彰显。
窄带宽高清视频,通用算力包揽
在迈过“能不能”的门槛之后,CPU的通用性带来的灵活性,以及软件生态上的优势,让其能够在更多的AI场景,发挥更大的作用。
以在线上大量应用的窄带高清业务为例,传统上是一个串行异构的工作流。起始和收尾的视频编解码一般用CPU处理,因为CPU的控制精度更好,可以适配更多的编解码算法,有更多的优化能力。窄带高清希望用更高的压缩率、更低的带宽,去传输更高质量的视频,但高压缩率会影响视频质量,所以中间环节要引入GPU,通过深度学习和推理把图像优化,因为CPU的并行算力不够,无法达到直播的要求。

视频数据流从CPU解码后转给GPU优化,再转回CPU编码,引入的GPU提高了复杂度,不仅要针对GPU进行大量的开发,还要面对GPU的利用率问题。在这个流程中,GPU只做了视频增强,利用率不高,而且不能像CPU一样按需使用,用完就释放——以其紧俏度,之后就再也拿不到资源了。
通过AMX把推理性能提升7倍,96 vCPU的阿里云第八代企业级实例g8i,效果可以与32 vCPU加单卡A10(GPU)的组合相匹配。视频的解码、增强、编码不用切换平台,大大提升了数据流转的效率。CPU通用性好的优点也体现出来,软件层面代码零改造,硬件资源不做视频增强,还可以继续做视频编解码或其他业务,不会造成算力的损失。
One More Thing
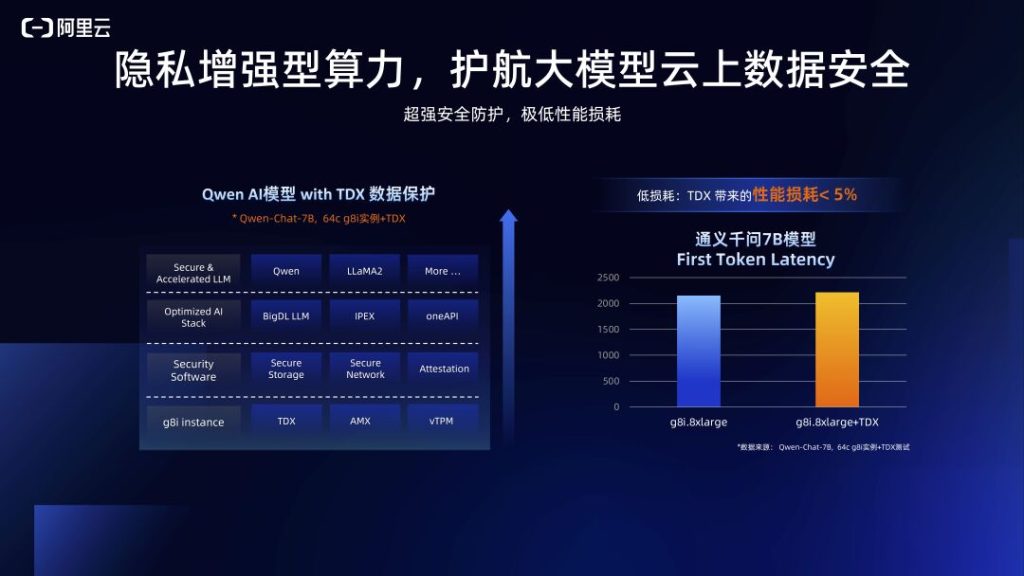
大模型是所属公司的核心资产,阿里云底层的CIPU(Cloud Infrastructure Processing Units,云基础设施处理器)架构通过可信根做了全流程可信的校验操作,结合把虚拟机做成安全隔离环境的TDX(Trust Domain Extensions,信任域扩展)机密计算技术,全流程保障数据安全。

阿里云的研发团队与英特尔深度合作、逐步优化,将启用机密计算TDX能力的第八代实例上运行通义千问70亿模型的性能损耗控制在5%以内,可以高性能跑好大模型的同时,保证大模型在云上的数据安全,通过第八代实例完美解决了高性能和高安全看似矛盾的两大痛点。这也是第八代企业级实例相对于线下或前几代实例的另一个核心优势。
与其临渊羡鱼,不如推而有理,CPU可能更适合你。