2026 Open AI Infra Summit特辑|邱宇弟:破局 Scale Up 未来发展瓶颈 UALink 2.0 协议演进与分析
在2026 Open AI Infra Summit 上,
阿里云高速互连架构师邱宇弟
发表了主题为《破局Scale Up 未来发展瓶颈:UALink 2.0 协议演进与分析》的演讲
以下内容根据邱宇弟演讲整理,略有删减

UALink的使命
随着大模型的发展,包括参数量也越来越大,单卡无法满足需求,需要一个更大的Scale Up的互联规模。UALink正是在这样一个背景下诞生的。
UALink是个面向Scale Up的、开放的互联协议。首先,它是开放的行业标准,是行业厂商一起共建的生态,而非某一家厂商的私有协议。第二,它面向的是专门针对加速器的Scale Up互联。第三,它是内存语义的、低延迟的互联,它提供的是Load-Store语义的直接内存访问。第四,它是PCIe、CXL和以太网的补充,而不是替代的关系:PCIe更多的是面向设备的互联;CXL更多的场景是在通用计算领域下的内存扩展;以太网更多的是Scale Out;UALink更多的是面向Scale Up的互联。第五,它是多厂商共同竞争的生态和市场。我们可以看到行业上已经有非常多的厂商,包括Switch或者加速器厂商,他们可以共同针对UALink协议去展开产品设计,产生更好的合作和发展。

上图是目前UALink联盟组织的成员,目前已经有超过100家会员,董事会成员有12家。阿里巴巴是来自中国区的董事会成员。
联盟内部涵盖了非常多类型的厂商,包括云计算产商、CPU和GPU产商、Switch产商和IP产商。AMD、AWS非常积极的支持UALink的加速器, Synopsys开发了对应UALink的IP,AsteraLabs在做UALink的Switch。国内厂商,如楠菲微电子研发了UALink Switch,国内很多GPU厂商也在积极支持UALink。
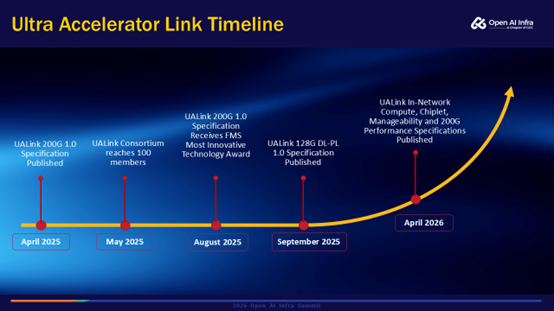
上图是UALink演进的时间线。UALink在2024年左右开始推动整个协议的构建。2025年4月份发布了UALink1.0 Spec,在当年5月已经超过了100家会员,到9月的时候继续发布了基于128G的DL-PL规范。2026年的4月,UALink又开放了4个新的Spec,分别是关于在网计算、DL-PL规范,Chiplet规范,以及管理规范。
UALink 1.0基本规范
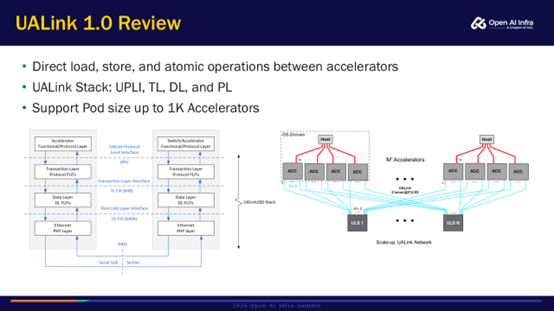
首先快速回顾一下UALink 1.0。UALink 1.0提供了内存语义的Load、Store、Atomic的加速器访问。它的整体协议栈分为4层:最上面是UPLI(UALink Protocol Layer Interface,UALink协议层接口)层,它提供的功能是给加速器提供内存语义总线接口,包括像请求、响应之类的通道;第二层是Transaction Layer事务层,TL提供的功能是把上面这些内存语义的请求事务转换成固定大小64Byte TL FLIT,并在这一层提供了基于信用的流控机制;再下一层是Data Layer数据层,DL这一层提供的功能是把64Byte TL FLIT再打包成一个更大的640Byte FLIT,并在这一层提供了CRC校验,以及LLR链路层重传的功能;最后一层是物理层,基于标准的以太网,只在上面做了少量改动。UALink是面向加速器的Scale Up互联,所以它的设计理念是让整个协议栈比较轻,只加必要的功能。较薄的协议开销让整体延迟较低、带宽效率更高。
上图右侧是系统架构,UALink 1.0支持一层的互联,最大可支持规模是1K节点。
UALink 2.0的演进
2026年4月初发布了4个新的Spec,包括Common(公用)Spec 2.0,主要是额外增加了在网计算的功能;第二个是UALink 200G DL-PL Spec 2.0;第三个是UALink管理Spec 1.0;第四个是UALink Chiplet Spec 1.0。
UALink Common Specification 2.0: In-Network Compute

首先介绍一下UALink 2.0 Common Spec中新增的在网计算功能。NVIDIA的网络交换机中提供了SHARP功能,具有在网计算的能力。UALink新推出的功能本质上也是对标SHARP的,把一些集合通信的操作从GPU卸载到交换机上,可以提升整个系统的带宽、降低延迟。这些功能主要针对Broadcast和Reduce的操作,对应到集合通信原语,加速的主要是All Reduce的算子。
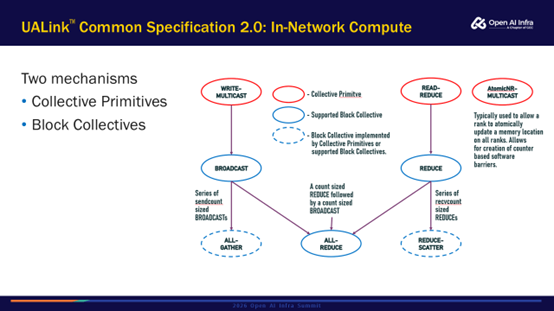
在UALink2.0中提供了两种机制:Collective Primitives和 Block Collectives。第一种机制是上图中红框的部分,它还是以内存语义单条读写的大小实现。UALink单个请求最大256Byte,图中Write-Multicast和Read-Reduce请求是以256Byte的粒度去发送单条请求。这个实现与NVIDIA的SHARP是比较类似的,还是以内存语义的粒度。
另一个是额外提供的Block level的方案,以块数据段的粒度去进行在网计算操作。例如上一种机制的粒度是256Byte,那么在Block level可以是以几KB或者几MB的粒度。这样的好处是把整块的数据卸载到交换机上,对于加速器SM计算资源的占用会更少。
这两种机制是互补关系,在不同场景下会有不同的适用范围。
UALink 200G Data Link and Physical Layers (DL/PL) Specification 2.0
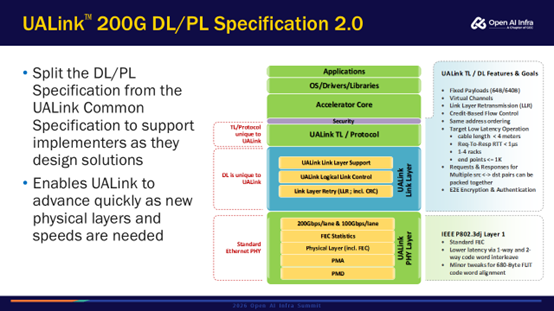
UALink DL/PL Spec 2.0有了很大的变化。在1.0中,Spec涵盖了UPLI、TL、DL、PL层,但是在2.0中把DL、PL单独拆分出来做一个独立的Spec。因为DL、PL和上面的协议层关系并不是很大,把它们拆开之后可以分别独立演进。例如,物理层的速率发展的速度和协议层的速度可能不一样,独立演进让链路层可以更快跟上速率发展的速度。
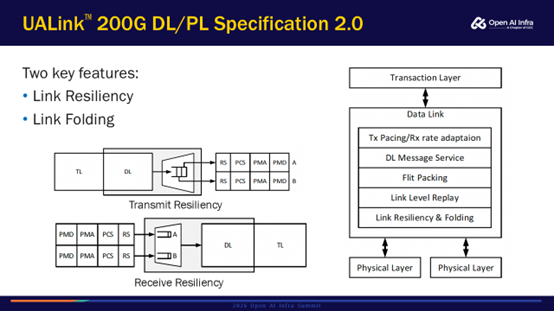
Spec2.0额外提供两个主要功能:链路弹性(Link Resiliency)和链路折叠(Link Folding)。目前集群规模越来越大,链路故障率也会越来越高,链路弹性功能有助于提高稳定性。图右的DL下面可以有两个PL,对应两个链路,如果有一个链路坏了,依然可以用另外一条链路维持正常的功能,使得DL层依旧能提供链路层重传的功能。如果是一个DL对应一个PL的设计,那么如果一个链路断了,应用程序是会挂掉的,需要重新启动。在链路弹性的特性下,一个物理层的链路挂了之后,它可以通过另一个物理层的链路继续传输,此时的应用程序其实不会立马挂掉。链路折叠针对一些低功耗场景,可以主动关闭一些链路以减少能耗。
UALink Manageability Specification 1.0
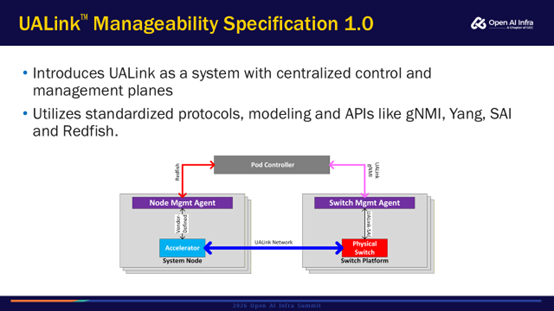
UALink最近也发布了关于管理的Spec。UALink的管理是以一个Pod Controller作为集中式管理节点,在加速器节点上有一个管理的代理(Node Mgmt Agent),在交换机有一个Switch管理代理(Switch Mgmt Agent)。协议里定义和规范了Pod Controller和加速器节点是基于Redfish标准;定义了Pod Controller和Switch管理代理通过UALink gNMI接口;定义了交换机上管理代理和物理交换机是通过UALink SAI接口互联。这些接口其实都是原本行业内的一些标准的接口,只不过UALink在这个基础上做了一些额外修改。
UALink Chiplet Specification 1.0
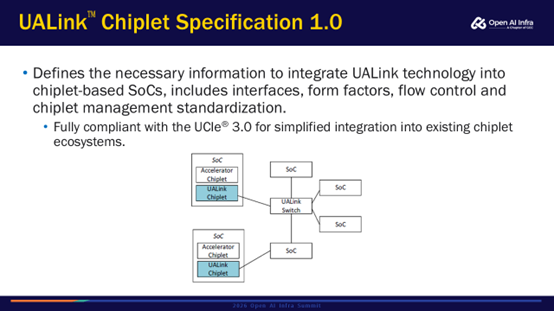
Chiplet可以降低整体的开发成本,以及芯片成本。UALink Chiplet Spec整体是兼容UCIe 3.0标准的。加速器厂商可以更专注于计算芯片的设计,只需要从供应商那里获取UALink接口的Chiplet去集成即可。加速器芯片和UALink接口芯片也可以采用不同的工艺。除了加速器,UALink Switch也可以用Chiplet, Switch设计厂商可以专注于Crossbar交换架构的设计,不用太关注接口芯片的设计。
总结
首先,技术层面看,UALink专门面向Scale Up的场景,不会引入很多额外其他的开销,它的协议栈设计比较有针对性且轻量化,因此UALink的协议控制器面积和功耗都是比较低的,整体延迟也会比较低。协议内的TL、DL都是极致打包的结构,带宽效率也非常高,在一些场景下最高可以做到93%以上。

其次是生态建设。互联协议对于单个厂商来说,原本需要有非常强的整合能力才可能解决从加速器、Switch,到包括IP协议等环节的问题。Scale Up协议更需要的是联盟以及生态的构建。UALink非常注重的是整个生态,包括国内和国外厂商的共建,已经吸引了超过100家合作成员。
第三点是关于Spec的完整性。除了近期发布的这4个Spec,UALink后续还有陆续推出兼容性、测试等Spec。
第四点是目前厂商的支持度,无论是国内外的IP厂商、GPU厂商和Switch厂商,有非常多的合作伙伴。预计在2027年会有基于UALink的量产产品。